Example how to analyze DynamoDB item changes with Kinesis and Athena created with Terraform
This post is how stream data changes of a DynamoDb table via Kinesis Data Stream and Kinesis Firehose to S3, and analyze the data with Athena
Why?
The data of a DynamoDb table is not so easy to analyze as a RDS with e.g., the pgAdmin. It will be somehow possible with scan operation but it's in the most cases not recommented.
Another possibility is the export to S3 functionylity.
In this post, it's described to use streams. Since 11/2020, it is also possible to use kinesis data streams for such a case.
That also allows to analyze changes and use it for audits.
A example with DynamoDb streams are here:
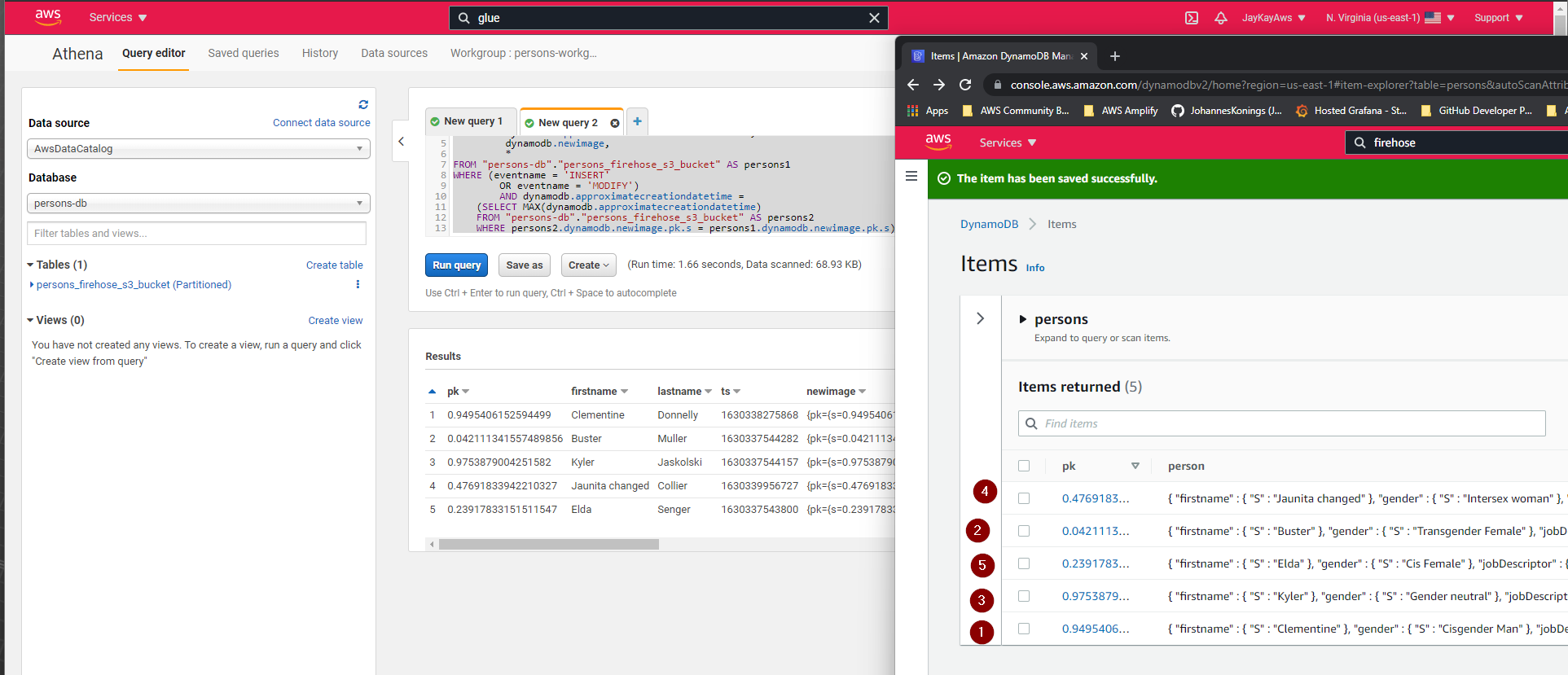
Architecture
The lambda is sending fake person data to DynamoDb. The integration of the Kinesis Data Stream into the DynamoDb is connected to the Kinesis Firehose, which sends the changes partitioned to the S3 bucket.
The Glue crawler will recognize the data structure and create a table, which can be accessed from Athena to analyze the data.
Let's see the certain building blocks
Lambda (for data creation)
The Lambda is created with a module from serverless.tf.
The source code is here
The number of created persons depends on the test event.
{
"batchSize": 5
}DynamoDb and Kinesis Data Stream
This is the creation of the DynamoDb with the Kinesis Data Stream.
resource "aws_dynamodb_table" "aws_dynamodb_table" {
name = var.TABLE_NAME
billing_mode = "PAY_PER_REQUEST"
hash_key = "pk"
attribute {
name = "pk"
type = "S"
}
}
resource "aws_kinesis_stream" "aws_kinesis_stream" {
name = "${var.TABLE_NAME}-data-stream"
shard_count = 1
encryption_type = "KMS"
kms_key_id = aws_kms_key.aws_kms_key.arn
}
resource "aws_dynamodb_kinesis_streaming_destination" "aws_dynamodb_kinesis_streaming_destination" {
stream_arn = aws_kinesis_stream.aws_kinesis_stream.arn
table_name = aws_dynamodb_table.aws_dynamodb_table.name
}That adds to the DynamoDb, a Kinesis Data Stream, and connects it to the DynamoDb.
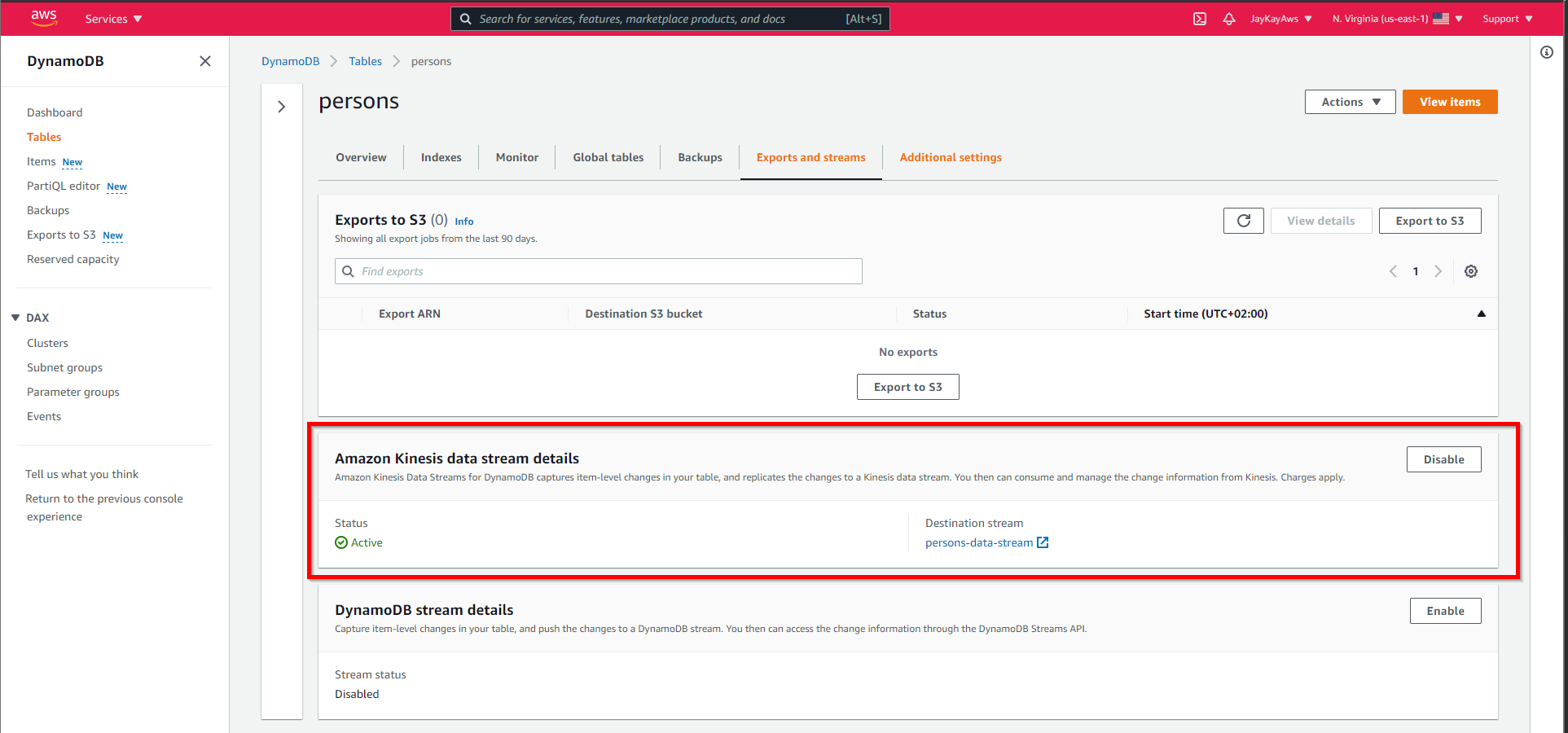
Kinesis Data Firehose and S3 Bucket
Kinesis Data Firehose is the connection between the Kinesis Data Stream to the S3 Bucket.
Unfortunately, Firehose stores the JSONs without a linefeed. Therefore it's a lambda for conversion is necessary.
More about that is described in this post
Besides policy configuration, it looks like this.
resource "aws_kinesis_firehose_delivery_stream" "aws_kinesis_firehose_delivery_stream" {
name = local.firehose-name
destination = "extended_s3"
kinesis_source_configuration {
kinesis_stream_arn = aws_kinesis_stream.aws_kinesis_stream.arn
role_arn = aws_iam_role.aws_iam_role.arn
}
extended_s3_configuration {
role_arn = aws_iam_role.aws_iam_role.arn
bucket_arn = aws_s3_bucket.aws_s3_bucket.arn
processing_configuration {
enabled = "true"
processors {
type = "Lambda"
parameters {
parameter_name = "LambdaArn"
parameter_value = "${module.lambda_function_persons_firehose_converter.lambda_function_arn}:$LATEST"
}
}
}
cloudwatch_logging_options {
enabled = true
log_group_name = aws_cloudwatch_log_group.aws_cloudwatch_log_group_firehose.name
log_stream_name = aws_cloudwatch_log_stream.aws_cloudwatch_log_stream_firehose.name
}
}
}Details are here
The delivery of the data to the S3 bucket is buffered. Here are the default values.
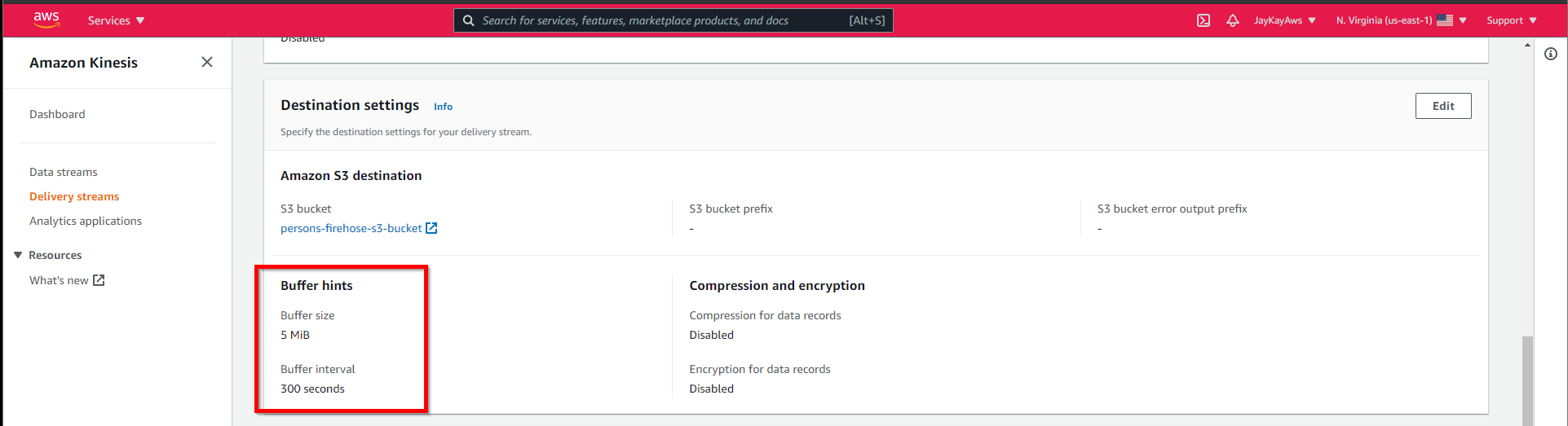
Glue crawler
Athena needs a structured table for the SQL queries. The Glue crawler creates this from the data in the S3 bucket.
resource "aws_glue_crawler" "aws_glue_crawler" {
database_name = aws_glue_catalog_database.aws_glue_bookings_database.name
name = local.glue-crawler-name
role = aws_iam_role.aws_iam_role_glue_crawler.arn
configuration = jsonencode(
{
"Version" : 1.0
CrawlerOutput = {
Partitions = { AddOrUpdateBehavior = "InheritFromTable" }
}
}
)
s3_target {
path = "s3://${aws_s3_bucket.aws_s3_bucket.bucket}"
}
}Details here
For test purposes, it's enough to run the crawler before any analysis. Scheduling is also possible.
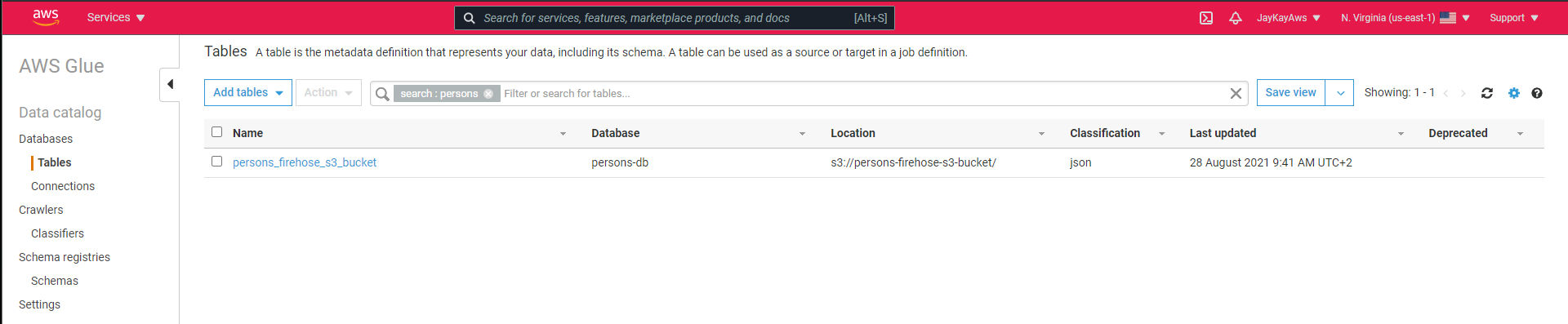
That creates this table, which is accessible by Athena.
Athena
For Athena it needs an S3 bucket for the query results and, for better isolation to other projects, a workgroup.
locals {
athena-query-results-s3-name = "${var.TABLE_NAME}-query-results"
athena-workgroup-name = "${var.TABLE_NAME}-workgroup"
}
resource "aws_s3_bucket" "aws_s3_bucket_bookings_query_results" {
bucket = local.athena-query-results-s3-name
acl = "private"
versioning {
enabled = true
}
server_side_encryption_configuration {
rule {
apply_server_side_encryption_by_default {
kms_master_key_id = aws_kms_key.aws_kms_key.arn
sse_algorithm = "aws:kms"
}
}
}
}
resource "aws_athena_workgroup" "aws_athena_workgroup" {
name = local.athena-workgroup-name
configuration {
enforce_workgroup_configuration = true
publish_cloudwatch_metrics_enabled = true
result_configuration {
output_location = "s3://${aws_s3_bucket.aws_s3_bucket_bookings_query_results.bucket}/output/"
encryption_configuration {
encryption_option = "SSE_KMS"
kms_key_arn = aws_kms_key.aws_kms_key.arn
}
}
}
}Details here
Analysis
First select the new workgroup.
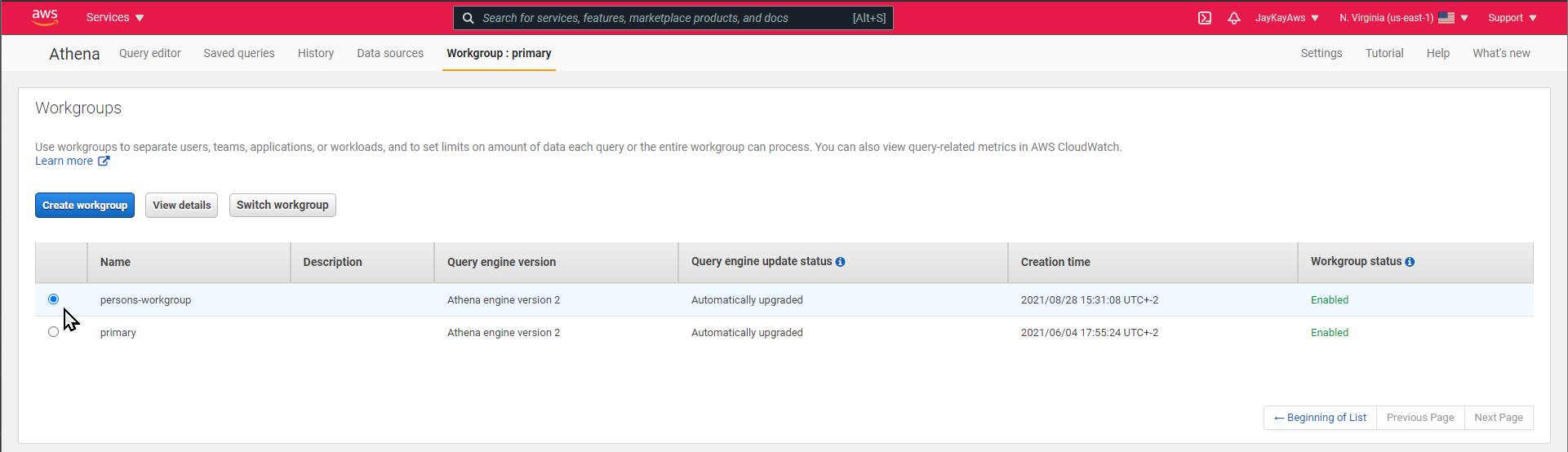
And than the new Database.
Query example
DynamoDb sends the changes of an item as INSERT, MODIFY or REMOVE. To the current data of the table, this Query will work.
SELECT dynamodb.newimage.pk.s AS pk,
dynamodb.newimage.person.M.firstname.s AS firstname,
dynamodb.newimage.person.M.lastname.s AS lastname,
dynamodb.approximatecreationdatetime AS ts,
dynamodb.newimage,
*
FROM "persons-db"."persons_firehose_s3_bucket" AS persons1
WHERE (eventname = 'INSERT'
OR eventname = 'MODIFY')
AND dynamodb.approximatecreationdatetime =
(SELECT MAX(dynamodb.approximatecreationdatetime)
FROM "persons-db"."persons_firehose_s3_bucket" AS persons2
WHERE persons2.dynamodb.newimage.pk.s = persons1.dynamodb.newimage.pk.s);
Cost Alert 💰
⚠️ Don't forget to destroy after testing. Kinesis Data Streams has costs per hour
Code
https://github.com/JohannesKonings/test-aws-dynamodb-athena-tf