Example how to analyze DynamoDB item changes with Kinesis and Athena created with CDK
This post is how stream data changes of a DynamoDb table via Kinesis Data Stream and Kinesis Firehose to S3, and analyze the data with Athena. Build with CDK.
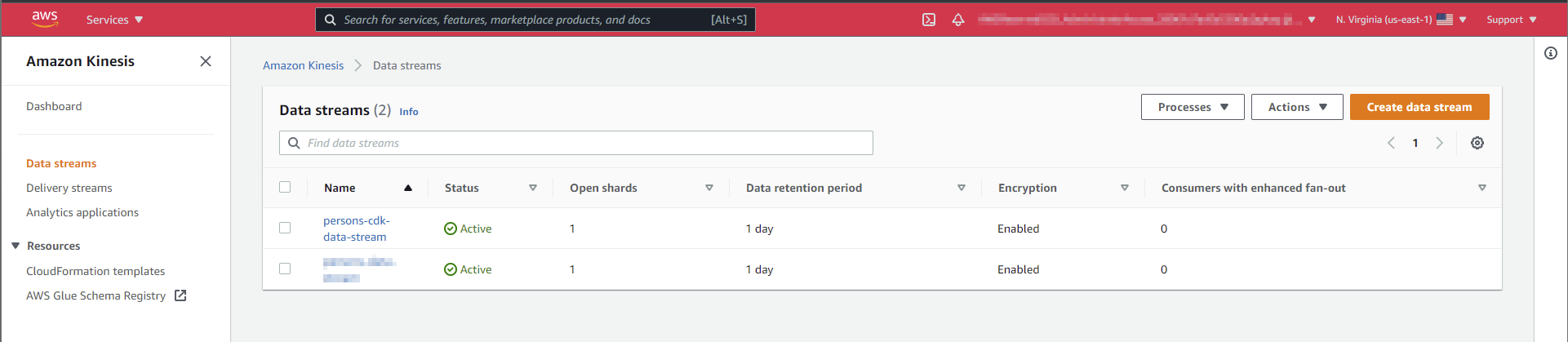
This is the same like described here, but instead of terraform it's build with CDK.
To bootstrap the project run this command: cdk init app --language typescript
Further information are here
All the services are in this file.
Updates
2022-09-11: Add prefix for kinesis data firehose S3 destination 2022-08-13: CDK migrated to v2
KMS key
This creates are KMS key with an alias to encrypt the data in the created services.
const kmsKey = new kms.Key(this, "kmsKey", {
enableKeyRotation: true,
});
kmsKey.addAlias(name);DynamoDb and Kinesis Data Stream
This is the creation of the DynamoDb with the Kinesis Data Stream.
const stream = new kinesis.Stream(this, "Stream", {
streamName: `${name}-data-stream`,
encryption: kinesis.StreamEncryption.KMS,
encryptionKey: kmsKey,
});
const table = new dynamodb.Table(this, "Table", {
tableName: name,
partitionKey: { name: "pk", type: dynamodb.AttributeType.STRING },
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
encryption: dynamodb.TableEncryption.CUSTOMER_MANAGED,
encryptionKey: kmsKey,
kinesisStream: stream,
});That adds to the DynamoDb, a Kinesis Data Stream, and connects it to the DynamoDb.
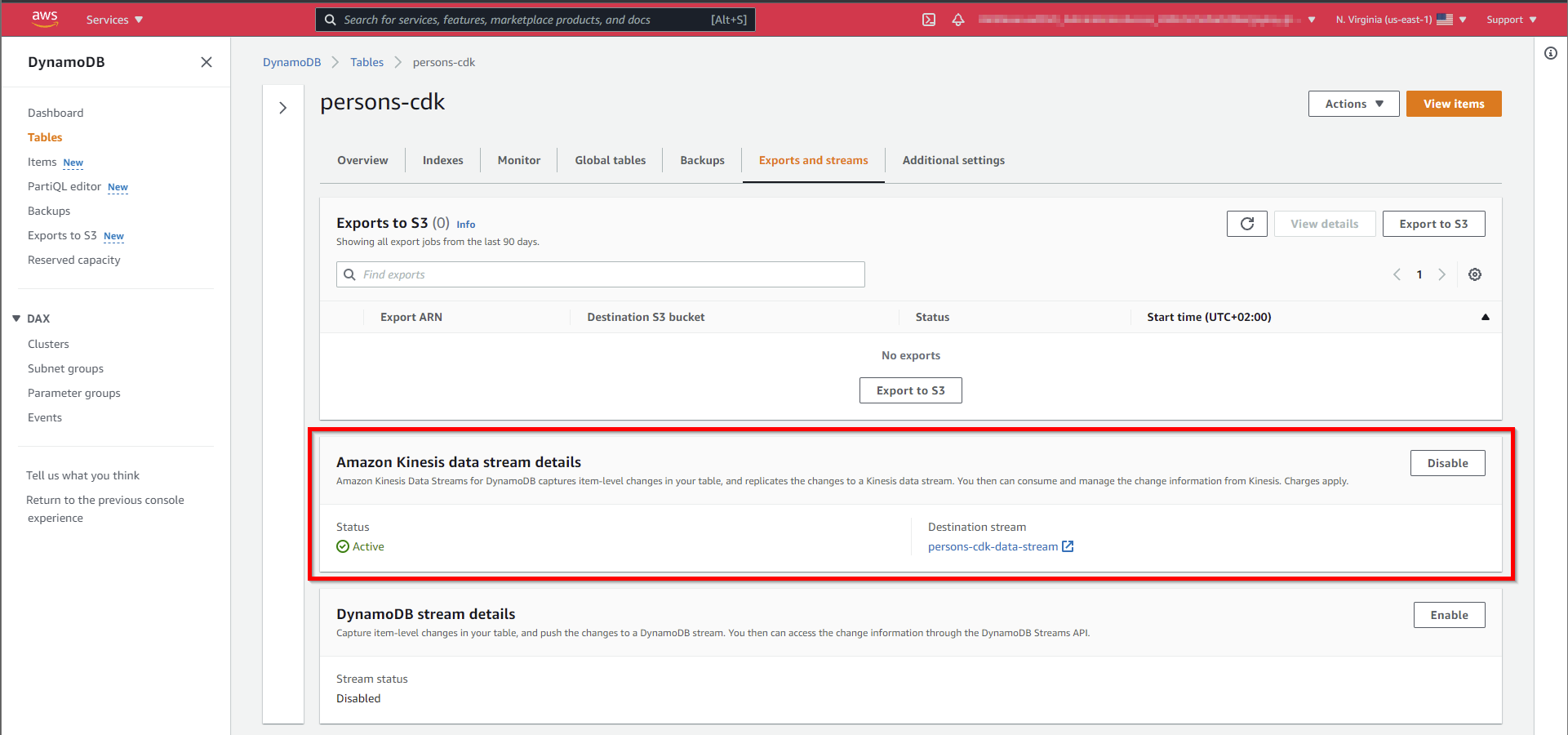
Kinesis Data Firehose and S3 Bucket
Kinesis Data Firehose is the connection between the Kinesis Data Stream to the S3 Bucket.
Unfortunately, Firehose stores the JSONs without a linefeed. Therefore it's a lambda for conversion is necessary.
More about that is described in this post
To have the kinesis firehose data isolated under a "namespace" we use a prefix.
It looks like this.
const firehoseBucket = new s3.Bucket(this, "firehose-s3-bucket", {
bucketName: `${name}-firehose-s3-bucket`,
encryptionKey: kmsKey,
});
const processor = new lambda.NodejsFunction(this, "lambda-function-processor", {
functionName: `${name}-firehose-converter`,
timeout: cdk.Duration.minutes(2),
bundling: {
sourceMap: true,
},
});
const lambdaProcessor = new LambdaFunctionProcessor(processor, {
retries: 5,
});
const ddbChangesPrefix = "ddb-changes";
const s3Destination = new destinations.S3Bucket(firehoseBucket, {
encryptionKey: kmsKey,
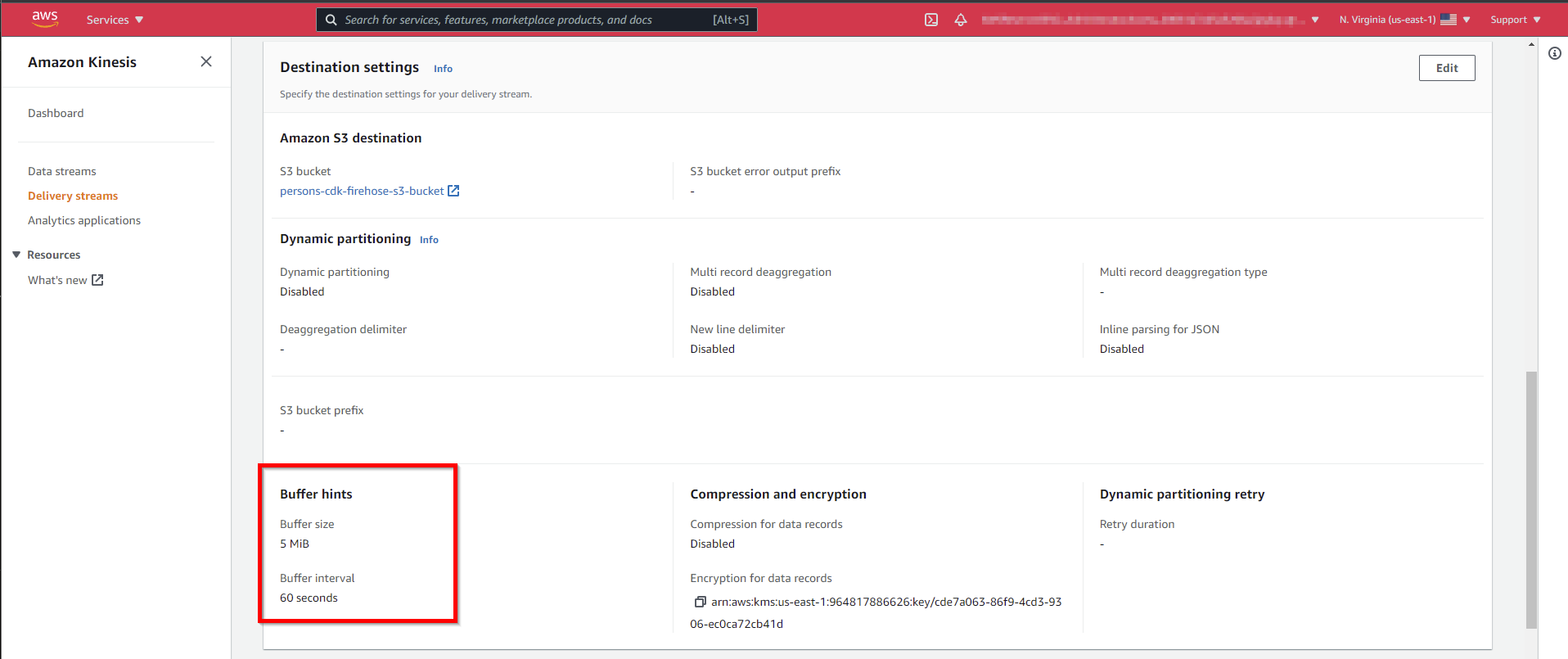
bufferingInterval: cdk.Duration.seconds(60),
processor: lambdaProcessor,
dataOutputPrefix: `${ddbChangesPrefix}/`,
});
const firehoseDeliveryStream = new firehose.DeliveryStream(this, "Delivery Stream", {
deliveryStreamName: `${name}-firehose`,
sourceStream: stream,
destinations: [s3Destination],
});The delivery of the data to the S3 bucket is buffered. Here are the default values.
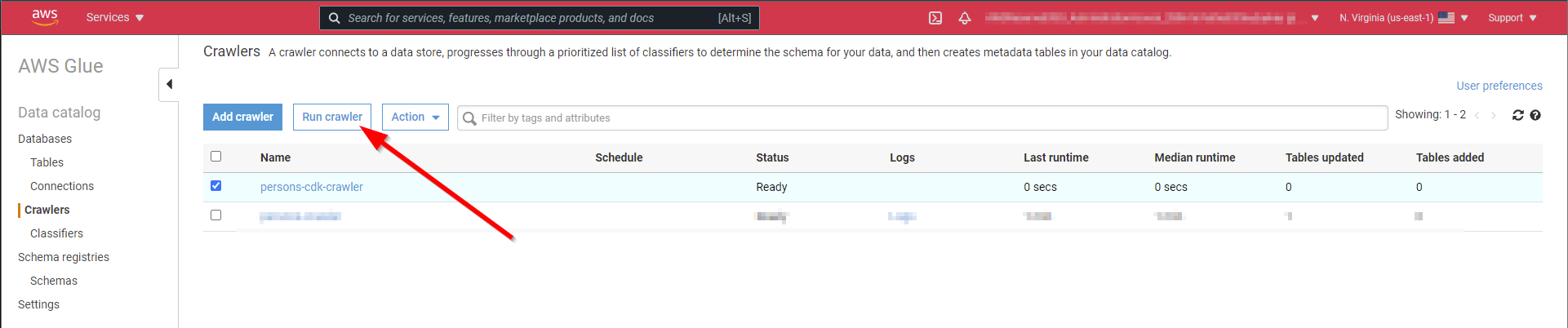
Glue crawler
Athena needs a structured table for the SQL queries. The Glue crawler creates this from the data in the S3 bucket below the configured prefix.
The glue crawler isn't a L2 construct yet. So it needs a L1 construct. See here more about L1 - L3.
There is already a github issue to create a L2 construct for the glue crawler.
const getSecurityConfiguration = new iam.PolicyDocument({
statements: [
new iam.PolicyStatement({
actions: ["glue:GetSecurityConfiguration"],
resources: ["*"],
}),
],
});
const roleCrawler = new iam.Role(this, "role crawler", {
roleName: `${name}-crawler-role`,
assumedBy: new iam.ServicePrincipal("glue.amazonaws.com"),
inlinePolicies: {
GetSecurityConfiguration: getSecurityConfiguration,
},
});
const glueDb = new glue.Database(this, "glue db", {
databaseName: `${name}-db`,
});
const glueSecurityOptions = new glue.SecurityConfiguration(this, "glue security options", {
securityConfigurationName: `${name}-security-options`,
s3Encryption: {
mode: glue.S3EncryptionMode.KMS,
},
});
const crawler = new glue.CfnCrawler(this, "crawler", {
name: `${name}-crawler`,
role: roleCrawler.roleArn,
targets: {
s3Targets: [
{
path: `s3://${firehoseBucket.bucketName}/${ddbChangesPrefix}`,
},
],
},
databaseName: glueDb.databaseName,
crawlerSecurityConfiguration: glueSecurityOptions.securityConfigurationName,
});
// const glueCrawlerLogArn = `arn:aws:logs:${cdk.Stack.of(this).region}:${cdk.Stack.of(this).account}:log-group:/aws-glue/crawlers:log-stream:${crawler.name}`
const glueCrawlerLogArn = `arn:aws:logs:${cdk.Stack.of(this).region}:${cdk.Stack.of(this).account}:log-group:/aws-glue/crawlers*`; //:log-stream:${crawler.name}`
const glueTableArn = `arn:aws:glue:${cdk.Stack.of(this).region}:${cdk.Stack.of(this).account}:table/${glueDb.databaseName}/*`;
const glueCrawlerArn = `arn:aws:glue:${cdk.Stack.of(this).region}:${cdk.Stack.of(this).account}:crawler/${crawler.name}`;
roleCrawler.addToPolicy(
new iam.PolicyStatement({
resources: [
glueCrawlerLogArn,
glueTableArn,
glueDb.catalogArn,
glueDb.databaseArn,
kmsKey.keyArn,
firehoseBucket.bucketArn,
`${firehoseBucket.bucketArn}/*`,
glueCrawlerArn,
],
actions: ["logs:*", "glue:*", "kms:*", "S3:*"],
}),
);For test purposes, it's enough to run the crawler before any analysis. Scheduling is also possible.
That creates this table, which is accessible by Athena.
Athena
For Athena it needs an S3 bucket for the query results and, for better isolation to other projects, a workgroup.
const athenaQueryResults = new s3.Bucket(this, "query-results", {
bucketName: `${name}-query-results`,
encryptionKey: kmsKey,
});
new athena.CfnWorkGroup(this, "analytics-athena-workgroup", {
name: `${name}-workgroup`,
workGroupConfiguration: {
resultConfiguration: {
outputLocation: `s3://${athenaQueryResults.bucketName}`,
encryptionConfiguration: {
encryptionOption: "SSE_KMS",
kmsKey: kmsKey.keyArn,
},
},
},
});How to anylyze the data see also here
Cost Alert 💰
⚠️ Don't forget to destroy after testing. Kinesis Data Streams has costs per hour
Code
https://github.com/JohannesKonings/test-aws-dynamodb-athena-cdk